.--= HRAS =--.
Haplogroup Research Analytical Suite (HRAS), developed with Thomas Krahn and released in 2023, is the integration of my previous Y- and mtDNA frequency and diversity heatmap tools, the PhyloGeographer theoretical approximate migration calculator along with additional analytical functionality.
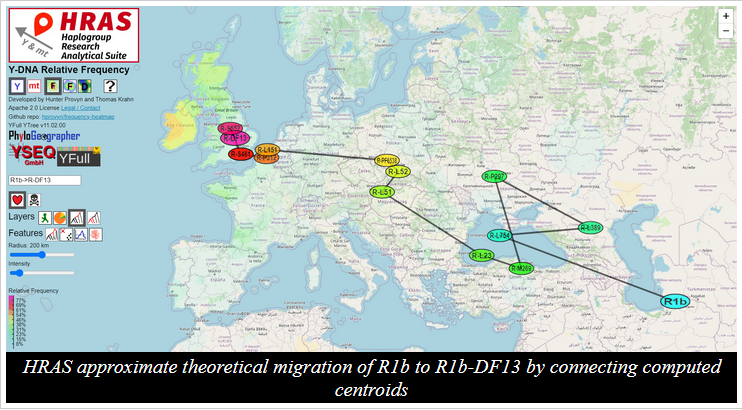
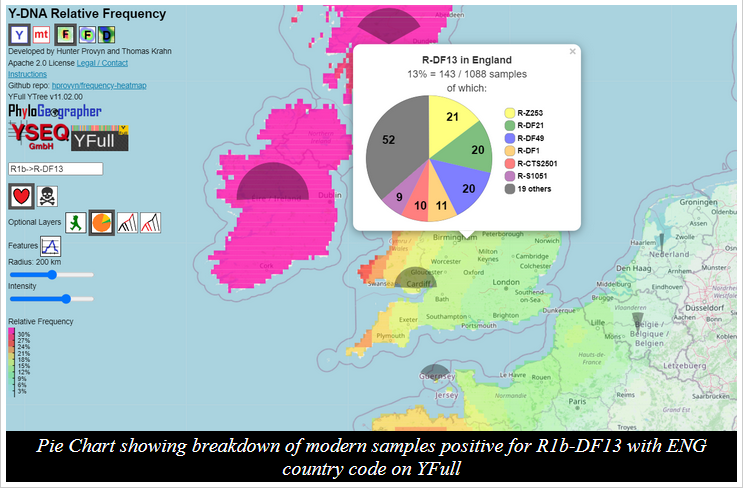
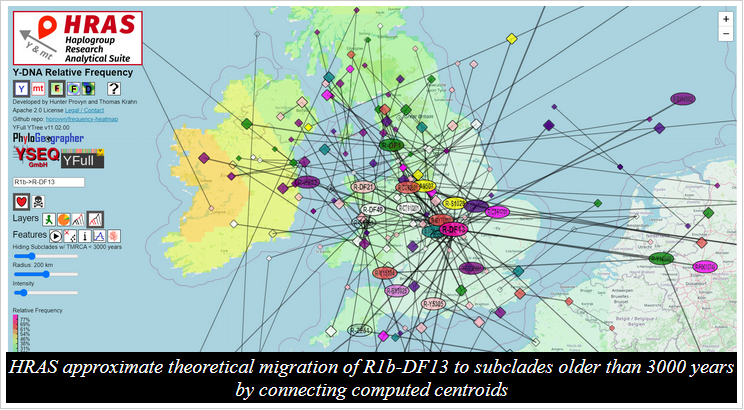
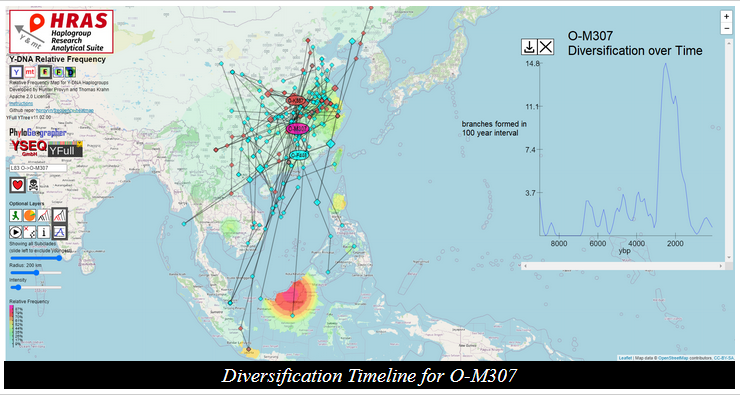
.--= Tools and Resources=--.

.--= Consulting and Commissioned Research =--.
Articles posted to this website and videos posted to my YouTube: https://www.youtube.com/@HunterProvyn
When a new relative views your subclade on HRAS they will find your commissioned research article or YouTube video through the new "Research Articles" feature.
"Thanks very much -- extremely helpful! I will work with these two kits to see if I can get one/both of them to test. " - Fred, 9/30/2021
- RE: STR Analysis for Dodson R1b-DF49>A11697/FT123392
.--= News =--.
5/24/2025 HRAS Updated to YFull YTree v13.03 3/20/2025 HRAS Updated to YFull YTree v13.02 3/18/2025 (YouTube) Three Ways J2b-L283 Broke the Mold 3/6/2025 (YouTube) Moksha-Mishar Tatar J2b-Y12000, Black Sheep of J2b-L283: Pannonian Avars who went to Middle Volga? 3/2/2025 (YouTube) Circassian J2b-L283 Likely Descends from Yamnaya Remnants from North of the Caucasus 2/27/2025 Perhaps the Most Divergent J2b-L283 37-STR Profile I’ve Ever Seen 2/24/2025 (YouTube) Vote for topic: Y-DNA of Dolmen Culture of Caucasus or Chaldean vs Assyrian Neo-Aramaic speakers 2/19/2025 Belgian's Closest Male Line Relatives are the Williams and Burgess clans of J2b-L283>..>Y15058>..>Y189978 2/18/2025 Which branch(es) of J2b-L283 could the Liburnians have been? 2/18/2025 HRAS Updated to YFull YTree v13.01 2/6/2025 (YouTube) DNA News - Horse Domestication, Rapa Nui, Ranis, 23andMe/Nebula, and new Analytical Tools Updates 2/4/2025 (YouTube) Could my Italian client with Y-DNA haplogroup L-L1320 descend from Parthian prince Vonones I? 1/29/2025 First Moroccan in J2b-L283 Splits European Jewish J2b-Y33795 12/31/2024 Ranis, Rethink, and Repeat: 45,000 year old remains from Ranis, Germany Upend Earliest Out-of-Africa Migration Theories 12/28/2024 Where did J2b-YP91 originate 2300 BCE? The jury is still out but some signs point east… 12/27/2024 HRAS Updated to YFull YTree v12.05 12/26/2024 (YouTube Short) J2b-Z622 and J2b-Z600 Ancestors Most Likely Lived near the Core Yamnaya Zone of the Lower Dnieper 11/2/2024 Phoenicians, Roman-mediated or Earlier Migration for T-Z710 in Europe? A Line by Line Analysis 10/31/2024 HRAS Updated to YFull YTree v12.04 10/30/2024 Haplogroup Stability now in STR Match Finder 9/8/2024 My E-CTS246/Z906 Client's Rare Gambian-related 7,000-10,000 Year Old Haplogroup Based on Clade Finder and STR Analysis 9/6/2024 HRAS Updated to YFull YTree v12.03 5/21/2024 STR Match Finder now uses Allele-specific STR Mutation Rates 5/18/2024 Celebrate 2024 “A Great Year For Research” with the Official J2b-L283 Calendar 5/17/2024 Q-YP937 13000 Years Distantly Related Lines in Mexico and South America 5/12/2024 HRAS Updated to YFull YTree v12.01 4/26/2024 HRAS Optimized Default Relative Frequency Scaling 4/24/2024 HRAS Migration Path Calculating Algorithm Fixed and Improved
4/20/2024 Implications of 2700 BCE Ancient Yamnaya J2b-L283 from Crihana-Veche, Moldova
3/26/2024 Refugees, Forerunners or Simply Uncommon? – J2b-L283 Paraclades in Sardinia and Tuscany
3/24/2024 Two Separate Phoenician or Roman-Mediated Migrations of J2b-M205 to Sicily predicted by STRs
3/10/2024 Late Antiquity Central Balkans I2-FT138628
3/4/2024 HRAS Updated to YFull YTree v12.00
2/15/2024 HRAS Bug Fix (+ Happy Year of the Loong): China and Chile assigned to wrong continent exclusion group
12/4/2023 HRAS Updated to YFull YTree v11.05
11/26/2023 Three mtDNA Haplogroup C1 Subclades in the Americas May Descend From a Yet-To-Be-Defined-By-SNPs Common Ancestor from the Americas
11/24/2023 New HRAS Feature: Include/Exclude Countries by Continent or Group
11/21/2023 New HRAS Feature: Research Articles
11/15/2023 J2a-M158 of Afghanistan, Pakistan, Punjab, Kazakhstan and Eastern Anatolia
9/4/2023 J2b-M205 Diversification Peaked During Uruk Period + the Invention of the Sail as the Vector to South Arabia and possibly Egypt
9/1/2023 The 2023 Worden Family Association Reunion will be October 6-9 in Fort Worden Historical State Park, WA, USA
8/18/2023 R1a-L1029 older than YFull/FTDNA estimates and found in 3rd century BCE La Tene sample in Czechia – Center of Expansion Estimated as Łódź
8/12/2023 J2a-Y143477 is the new second subclade under 7700 year old J2a-Y12599, cousin of Caucasus Hunter Gatherer KK1
8/10/2023 HRAS Updated to YFull YTree v11.04
7/3/2023 First YFull YTree sample from Himachal Pradesh is rare line of J2b-Z2432
6/8/2023 Three HRAS improvements since initial release - Outliers, Basal/Ancient Sample weights, IDL-crossing
6/1/2023 Phylogeographer and HRAS updated to YFull v11.03.00 - old URLs point to HRAS
5/8/2023 Sample from Quba, Azerbaijan is closest relative to J2b-M205 Jews of India – but they are 5000 years distantly related
4/20/2023 Hunter Provyn presented HRAS at “Traces of the past… Genetic and traditional genealogy in archaeological, historical and socio-cultural research” at Chorzow, Poland April 20th 2023
4/2/2023 Phylogeographer and Heatmaps updated to YFull v11.02.00
4/2/2023 J2b-L283 April 2023 Update
3/18/2023 Language does not always equal political-national self-identity
2/27/2023 I2-Y3120 as Dacian King Burebista’s Dynasty
2/24/2023 Phylogeographer and Heatmaps updated to YFull v11.01.00
2/9/2023 J2b-L283 February 2023 Update
1/4/2023 Phylogeographer and Heatmaps updated to YFull v10.08.00
12/15/2022 J2b-L283 Christmas 2022 WGS Upgrade Wish List
12/1/2022 Phylogeographer and Heatmaps updated to YFull v10.07.00
10/23/2022 mt Heatmap updated to YFull MTree 1.02.18072
10/19/2022 Phylogeographer and Heatmaps updated to YFull v10.06.00
10/04/2022 J2b-A28999 First Paraclade of J2b-L283 Established by two Hungarian WGS testers at YSEQ
9/17/2022 Allele-Dependent STR Mutation Rates Calculated from YFull YTree
8/30/2022 Dedicated Page to J2b-L283 Updates Created
7/21/2022 Iron Age E-Y20805 is a microcosm of the geographic distribution of E-V13
7/15/2022 83% of Socotrans descend from one J2b-M205 man who lived 3100 years ago
7/12/2022 Case Study 4 – Post Mortem of a Wrong Prediction by Rare STR Signature Match
6/24/2022 mtDNA Haplogroup J1 Relative Frequency Maps
6/22/2022 mt Relative Frequency Heatmap Released!
6/22/2022 YSEQ mt Clade Finder Released!
6/19/2022 ~2000 Year Old Ancient Branch of J2b-CTS11760 Predicted Based on Shared Rare STR Alleles
5/22/2022 Phylogeographer and Heatmaps updated to YFull v10.03.00
5/18/2022 J2b-L283 Update May 2022 - Phoenician Kerkouane and Late Avar Elite Hungary (YouTube)
5/15/2022 VPB-307 Late Avar Elite J2b-L283>YP91>YP181 dating to 9th Century found in Keszthely cemetery
5/13/2022 Iron Age J2b-L283>Z38240 Samples found in Phoenician city Kerkouane (Tunisia)
4/23/2022 New J2b-Y330017 Line of J2b-Z2453 Formed by Two Samples from Yemen having 8000 ybp TMRCA
4/18/2022 Samples from Yemen, Saudi Arabia and Syria split D shortly after the split from DE and have an Upper Paleolithic TMRCA
4/15/2022 Sample from Dhamar, Yemen Splits Prolific Middle East Subclade J1-FGC11
4/11/2022 Phylogeographer updated to YFull v10.02.00
3/30/2022 Влияние войны России на Украине на мужчин J2b-L283 и исследования гаплогрупп
3/30/2022 Impact of Russian War on Ukraine on J2b-L283 Men and Haplogroup Research
1/12/2022 Phylogeographer updated to YFull v10.00.00 (YouTube)
1/10/2022 Two J2b-M205>Y128487 men from Mosul predicted to descend from one man who lived over 3000 years ago
1/3/2022 J2b-Y210000 Polish Lineage of J2b-Z4133 from Late Antiquity or Early Middle Ages MRCA
1/2/2022 Sandžak Bosniak, Albanian, Macedonian and Balkan Turk attest to Iron Age origin of J2b-FT117099
12/17/2021 Oberallgäu Bavarian Sample Splits J2b-YP91 and Adds More Diversity North of the Alps
12/13/2021 New Tutorial - Using the Process of Elimination to Reject Potential STR Matches
12/12/2021 Two Men From Foggia Form Their Own New Line of J2b-Z1043
12/3/2021 Recent Progress and the Challenges of J-Z631 and J-Z1043 Origins
11/28/2021 Sample from Serbia Splits J2b-CTS6190 and Yields Insight into Migration to Etruria of J2b-CTS473
11/22/2021 Z8427 Found in WGS Tests Unites 2/3 of All J-Z1043 Living Descendants Into Single Child Branch (YouTube)
11/15/2021 WGS Testing Establishes New Relationships on YFull YTree That Big Y-700 Could Not (YouTube)
11/12/2021 Addendum to J2b-M205 Uruk Expansion of Sumerian Culture Video
10/7/2021 Hunter's Y-DNA Tutorial Part 5: STR Deletions (YouTube)
9/30/2021 Create Informative Content Using PhyloGeographer and Y Heatmap
9/17/2021 J2b-L283 in Hungary and the Pannonian Roman Keszthely Culture
9/12/2021 Religious Continuity Along J2b Male Lines - Sometimes Going Back At Least 1800 Years (Podcast)
9/5/2021 The Different Paths of the Sons of Slavic Chieftain I2-Y3120 who lived 200 BC
8/22/2021 J2b-L283 Research – J-FT103684 the Rare Sibling of J-PH1602 with a Trace of West Balkan Origins
8/16/2021 J2b-L283 News - August 2021 (YouTube)
8/16/2021 Patreon Commissioned Analysis – Iron Age R1a-CTS6 from Iran
8/14/2021 J2b-M205 – New samples corroborate origin in or near the Levant 5200 BC
8/11/2021 Patreon Commissioned Analysis - E-L674 - A 1700 Year Old Lineage Found in Gulf-Arabs and Israel and Palestine
8/11/2021 Patreon Commissioned Analysis - Bronze Age R1b-L21>A287 Likely Gaels
7/24/2021 20 Haplogroup Heatmaps From Various Regions of the World
7/10/2021 Don't miss an episode of my new podcast - Our Male Line Ancestors
3/7/2021 Corsican and Provençal J2b-L283 STRs
3/1/2021 Tatarstan and Bashkortostan harbor first Central Asian lineage of J2b-Z2432
2/22/2021 Geographically Diverse J2b-Y167175 – the Rare Sibling of J2b-M241
2/10/2021 How to Advance Your Male Line Research just from STRs
12/25/2020 New Basal Lineage of J-L283 in the Pannonian Basin
12/25/2020 Dane Shares Rare Stable STR Allele with Mishar Tatar-Moksha J2b-Y12000
11/13/2020 J-L283 in Sicily - The Undiscovered Country
11/4/2020 New YFull Language Codes Benefit Haplogroup Research
10/21/2020 STR Match Finder Improvements and Video Tutorial
10/12/2020 (video) Why is J-L283 so Interesting?
9/7/2020 Y Heatmap - Relative Frequency Map of Your Subclade
7/3/2020 Genetic Genealogy Can Break Down Our Biases
5/31/2020 West-Macedonian and Bulgarian Lineage of J-FGC55778’s Possible Relationship to a Peloponnesian Greek Obscured by a RecLOH
5/17/2020 New Swiss-Sicilian Lineage Predicted in J-FGC55778
4/25/2020 Four Lineages of J-Z1043 United Into J-FGC55778 – Explaining Their Common Divergent DYS385a=10
4/11/2020 J-L283 As Caucasus Hunter Gatherer Component in Yamnaya
4/10/2020 YSEQ’s Competitive new WGS Prices
3/29/2020 Population Growth By Region of the Empire Since Ancient Rome
3/21/2020 Phylogeographer Updated to YFull v8.03.00
3/18/2020 Eleven J-L283 Lineages of Poland
3/17/2020 YFull World Sampling Interactive Map
3/6/2020 YFull Sampling Rates by Region in Germany
3/1/2020 Geographic Distribution of YFull Samples
2/22/2020 J-Y45447 and Links to Modern South Arabian Languages
2/5/2020 Pre-Roman Origin of Jewish J-Z39653 Could Be Revealed By J-Z39655
2/4/2020 J-M102 Lineages of South Asia
2/3/2020 Phylogeographer Updated to YFull v8.01.00
2/1/2020 J-M205 – 3700 BC Diversification in the Southern Levant – Egypt – and Arabia
2/1/2020 G-Y12975 Major Jewish Lineage of Southern Europe
1/25/2020 G-M377 Diversity Across Eurasia and the Americas
1/17/2020 J-L283’s Armenian Connection
1/17/2020 PhyloGeographer Updated to YFull v8.00.00
1/12/2020 R-DF21 Computed Origin Near Isle of Man
1/5/2020 - J-CTS11760 Update – Still Looks Celtic
12/28/2019 - PhyloGeographer Updated to YFull v7.10.00
12/12/2019 - J-Z40052 Middle Bronze Age Migration from the Balkans to Sweden
12/8/2019 - Vote for Which Feature I Implement Next
12/6/2019 - PhyloGeographer Updated to YFull v7.09.01
12/1/2019 - J-L283 The Case For a North of the Black Sea Migration from W Asia to Europe
11/15/2019 - Video - November Development Update
11/15/2019 - Video - Which location to use for your YFull sample
11/14/2019 - Haplogroup Statistics
11/8/2019 - First Ancient J-Z631 Found in Roman Necropolis
11/3/2019 - J-M241 Syrian Christians of India descend from Bronze Age Collapse Levantine J-Y146401 • BY46462
11/3/2019 - YFull Cost Benefit Analysis
10/26/2019 - Release Notes for Update to YFull v7.09
10/6/2019 - STR Match Finder Correctly Predicted First European J-Z2432, an Azorean
9/27/2019 - New Collaboration System
8/27/2019 - Inspiring Thoughts from PhyloGeography
8/26/2019 - Testing the Accuracy through Simulation
8/23/2019 - Two Improvements Explained
8/10/2019 - Central Europeans Who Became Mokshas and Tatars
8/2/2019 - Pre-Roman Migration to Scotland
6/15/2019 - New Service - Deep Match Finding for Those With No Matches
6/15/2019 - Big Article! - R1a-M198
6/14/2019 - Big Article! - R1b-DF27
6/14/2019 - Version 3.0 of Algorithm released as Open Source
6/13/2019 - Haplogroup Q added
5/7/2019 - Pilgrimage to Caucasus Hunter Gatherer Kotias Klde Cave with locals, possible descendants
4/21/2019 - TMRCA dates displayed in migration
4/5/2019 - Haplogroup N entered the Baltic via Finland in 1600 BC
4/5/2019 - All my articles, neatly organized here
4/2/2019 - Outlier correction implemented
3/22/2019 - Find your matches in FTDNA projects using the STR Match Finder
11/27/2018 - New Y-DNA Consulting services
11/4/2018 - All haplogroup migrations computed except Q
11/4/2018 - Adam haplogroup project traces back to "Adam" from haplogroup root locations
10/9/2018 - Updated with all YFull regional codes
9/20/2018 - Y-DNA Haplogroup G calibrated with Ancient DNA
9/13/2018 - First Newsletter Sent